Operators, Not Agents: Engineering Structure Around LLMs
Why shipping agents isn't enough — and the pattern that fixes it


Everyone is shipping coding agents. An LLM in a loop that can read files, write code, run commands, and iterate.
The agent decides what to do, does it, checks the result, and repeats.
It works — until it doesn’t. The agent wanders off-scope. It skips verification. It decides it is done when it is not. It expands its own authority mid-run. It hallucinates a fix and moves on. These are not edge cases. They are the default behavior of an unconstrained agent operating on a real codebase.
The problem is not the LLM. LLMs are genuinely good at reading and writing code — understanding what code does, generating changes that fit the surrounding context. What they are not good at is structure, scope control, verification, and knowing when to stop.
This article proposes a pattern for running agents well. That pattern is the operator.
What is an operator?
An agent is the generic concept: an LLM in a loop with tools. An agent is general-purpose — it can do anything its tools and permissions allow. Cursor, Claude Code, Codex, and OpenHands are not agents themselves; they are harnesses — platforms that provide the conversation loop, tool dispatch, sandboxing, and workspace interaction. An agent is an LLM instance running inside a harness.
An operator is a way of structuring how agents work. It adds the structure that an agent does not have on its own: a declared scope, a fixed set of stages, deterministic tool integration, verification gates, and composition rules. An operator constrains the agent — it decides what the agent works on, what actions are available at each stage, and when the agent stops.

The distinction matters:
A bare agent chooses what to do next. The operator pattern defines what stages exist and in what order they run.
A bare agent has access to all its tools. The operator pattern restricts which tools are available at each stage — read-only tools during Inspect, write tools only during Correct and Repair.
A bare agent decides when it is done. The operator pattern enforces explicit stop conditions — verification passes, attempts exhausted, or scope exceeded.
A bare agent can work on anything. The operator pattern scopes work to a declared target — specific files, a single tool concern, a bounded repair task.
Agents come in only in the later stages of an operator, not at the beginning. An operator starts with deterministic execution, checks, and predefined recovery steps. Only if those fail does it escalate to agent-backed Suggest or Repair stages, where the LLM gets focused failure context — such as tool errors, failing files, and project conventions — and reasons about what to change.
The agent does the reasoning; the operator handles everything around it.
The scaffolding that matters
The standard agent loop is Think → Act → Observe. A model reasons about the current state, takes an action, observes the result, and repeats.

We do not try to replace this loop. We build the scaffolding that makes it work well:
Think is the model’s job. We give it the right context — project conventions, tool output, file diffs, prior stage results — and let it reason.
Act is where our structure matters. We constrain what actions are available, what scope the operator can touch, and what authority level it has. An operator does not get to choose its own tools or expand its own scope.
Observe is verification. We run the project’s real checks — linters, type checkers, test suites — and feed the results back. The agent observes ground truth, not its own assessment of whether the change was correctly made.
LLMs get better at thinking on their own. What does not improve automatically is the engineering around the loop: how you scope the work, how you verify it, and how you compose multiple operators into reliable workflows.
Five actions, no more
Every operator can take exactly five actions, run through a canonical flow:
Inspect — Gather evidence before changes. Read-only. (Deterministic tools)
Correct — Apply the known right answer — deterministic, policy-approved changes. (Deterministic tools)
Suggest — Propose improvements that tools can't fix mechanically. Read-only. (Agent, informed by tool output)
Repair — Make bounded semantic changes that deterministic tools cannot. (Agent)
Verify — Run required checks and classify the outcome. (Deterministic tools or agent)
Not every operator supports every action. A read-only analysis operator might only support Inspect and Verify. A formatting operator might support Inspect and Correct. An operator that fixes type errors might support Inspect, Repair, and Verify. The flow skips any stage the operator does not implement.
The important constraint is that these are the only actions. An operator cannot invent new stages, expand its scope mid-run, or skip verification. The structure is fixed; the model operates within it.
Each stage emits an artifact another actor can inspect. Inspect produces evidence. Correct produces a deterministic patch. Suggest produces LLM suggestions for what tools flagged but cannot fix. Repair produces a bounded semantic correction plus the triggering evidence. Verify produces a verdict and the failing outputs, if any. The system should be auditable from artifacts alone.
Inspect and Verify often use the same tools — the same linter, the same test runner. But they serve different purposes. Inspect gathers evidence before changes. Verify classifies the result after changes. Keeping them separate is how we ensure that making a change and confirming a change are never conflated.
The Least Powerful Executor
Every layer of this system follows the Least Powerful Executor model:
Use the least powerful executor that can reliably complete the task within a declared scope and authority. Keep verification as a separate completion gate.
In practice, this creates a four-level hierarchy. Each level only escalates to the next when it runs out of road:
Commands first. If
ruff checkcan find the problem, runruff check. Do not ask an LLM.Scripts wrap commands.
make lintpackages the project’s linting flow into a stable, named entry point. CI calls it. Developers call it. Operators call it. The same script everywhere.Orchestrators coordinate. An orchestrator narrows scope to changed files, runs tools in the right order, collects results, and decides whether escalation is needed. It is still deterministic — no LLM.
Operators only when needed. An LLM enters the picture only after commands, scripts, and orchestrators have done everything they can. The operator operates within an explicit scope and authority, making bounded semantic changes that deterministic tools cannot handle.
“Tools” here means the project’s own engineering tools — ruff, mypy, Black, pytest, Semgrep — not the tools an agent uses inside its harness (file editing, terminal commands, browser). An operator calls project tools directly, as standalone commands, without involving an LLM at all. The agent and its harness tools only enter during the Repair stage, when the project’s tools have found a problem they cannot fix on their own.
The relationship between tools and LLMs is complementary, not either-or:
Black can format code — but if a formatting change creates a downstream problem, Black has no way to reason about it. Inspect and Correct use Black. Repair uses an agent when Black is not enough.
mypy can detect type errors — it cannot fix them. Inspect uses mypy. Repair uses an agent, informed by mypy’s output.
Security scanners (Bandit, Semgrep, Trivy) can flag vulnerabilities — but deciding whether a finding is a real risk, and how to remediate it without breaking the application, is a judgment call. Inspect uses the scanner. Repair uses an agent with the scanner’s findings as context.
pytest can tell you a test failed — it cannot rewrite the test or the code under test. Inspect and Verify use pytest. Repair uses an agent.
The pattern is consistent: tools provide ground truth, agents provide reasoning. Tools detect, agents interpret and fix. Even in the Repair stage, the agent’s work is always context-enriched by tool output — it sees the exact linter error, the exact type violation, the exact test failure. It never reasons in a vacuum.
Every new operator should wrap a real tool first. The tool is the foundation.
Composable and modular
Operators are designed to be composed. A single operator wraps a single tool or concern. A parent operator orchestrates multiple child operators. The composition is explicit and structural, not emergent.
Every tool gets its own operator. Black gets a formatting operator. Ruff gets a linting operator. mypy gets a type-checking operator. Each sub-operator knows how to run its tool through all five stages using the project’s existing commands.
Sub-operators use agents to let their tools go further than the tools can go alone. A formatting sub-operator runs Black directly in its Inspect and Correct stages — no LLM involved. But when something goes wrong that Black cannot handle on its own (e.g., a formatting change that breaks an import or creates a conflict), the operator escalates to an agent in the Repair stage. That agent is role-prompted with the personality of the tool it serves — it thinks and acts like a formatting expert, not a general-purpose assistant. The operator adds a layer of intelligence on top of a deterministic tool, without replacing the tool.
The same pattern applies to any command-line tool. If it has a check mode and meaningful output, it can become a sub-operator.
A parent operator orchestrates multiple sub-operators. A Linter operator does not re-implement Black, Ruff, and mypy. It orchestrates their sub-operators:
Discover which tools are available in the project.
Run Inspect across all sub-operators in parallel.
Run Correct serially to avoid conflicts between deterministic fixes.
For failures that Correct cannot resolve, run Repair per sub-operator with an agent.
Run Verify across all sub-operators to confirm the results.
A Reviewer operator takes this one level further. It is composed of pillars — linting, docstrings, type annotations, tests, architecture, security — where each pillar is itself an operator that may compose sub-operators. The linting pillar reuses the Linter’s sub-operators directly. No duplication.
This is the pattern: tools become sub-operators, sub-operators compose into domain operators, domain operators compose into the Reviewer operator.
Independent operators can also be dispatched in parallel through a coordinator — a thin fan-out layer that assigns each operator its own scope (and optionally its own git worktree), runs them concurrently, and aggregates results. The coordinator itself makes no decisions. It dispatches, waits, and collects. All intelligence stays in the operators and their stage methods.
Scope and authority
Every operator run is bounded by two orthogonal concerns: scope and authority. Scope is explicit — the caller passes it as a parameter. Authority is implicit — the caller controls it by choosing which command to run. Neither is discovered or expanded by the operator itself.
Scope is what the operator may inspect or modify — the target area. A line range, a single file, a directory, a repository, or an explicit set of named files declared in advance. The same operator should work at any granularity the caller specifies.
Authority is what the operator may do — the maximum power level. From lowest to highest: inspect only, suggest, deterministic transform, bounded semantic edit. The caller controls authority by choosing which command to invoke — requesting an inspect grants Inspect-only authority.
Authority levels map to the five stages but they are not the same thing. The stages describe what happens; authority describes what is permitted. An operator that supports the Repair stage still runs at Inspect-only authority if the caller only requests inspection.
The two parameters are orthogonal because they vary independently:
Wide scope, low authority — inspect the entire repository, change nothing. A read-only analysis pass.
Narrow scope, high authority — semantic repair on a single file where mypy reported an error. Focused and bounded.
Wide scope, high authority — project-wide repair. Expensive, high-risk, requires strong verification.
Narrow scope, low authority — inspect one file. Cheapest and safest.
The rule is simple: scope and authority go in, the operator works within them, results come out. If the work requires a wider scope or higher authority than what was declared, the operator stops and reports what it could not accomplish. It does not expand its own boundaries.
Enforcing constraints
Scope and authority are only as real as their enforcement. Prompt text alone is advisory — the model can still call any available tool on any file. Real constraint enforcement requires multiple layers.
Soft constraints are the prompt itself: allowed directories, forbidden files, stop conditions, maximum change size. They guide a well-behaved model but cannot prevent violations. Necessary but not sufficient.
Medium constraints are persistent project-level configuration — AGENTS.md, pre-commit hooks, customization files — that survive across sessions and get re-injected on every request. More durable than a one-shot prompt because they are not subject to context compression or truncation. They standardize boundaries across all operators working in the same project.
Hard constraints enforce limits outside the model. Mounting only the relevant workspace into the sandbox. Restricting the tool list so write tools are unavailable when the operator should only inspect. Setting turn and budget caps. Hard constraints are the only layer that provides guarantees — if an edit tool is not in the allowed list, the agent cannot edit regardless of what the prompt says.
IAM and token permissions are the outermost ring. A service account that lacks write access cannot write regardless of what tools the agent has. A fine-grained GitHub token scoped to read-only content and write access limited to pull requests cannot push to main — even if the agent is compromised or the prompt is adversarial. IAM is the most durable form of constraint because it is enforced by the cloud provider, not by the agent framework.
The layers are complementary. Soft constraints reduce the frequency of unwanted actions — and as instruction following improves across model generations, their effectiveness compounds. Medium constraints ensure rules are consistent and durable. Hard constraints make violations impossible rather than merely unlikely. The same Least Powerful Executor principle applies: prefer hard enforcement over soft guidance, the same way we prefer ruff --fix over asking an LLM to fix formatting.
Execution and escalation
The system supports two execution modes:
Single-stage — run exactly one stage and exit.
Auto — the full intelligent progression: Inspect → Correct → Verify → Repair+Verify loop
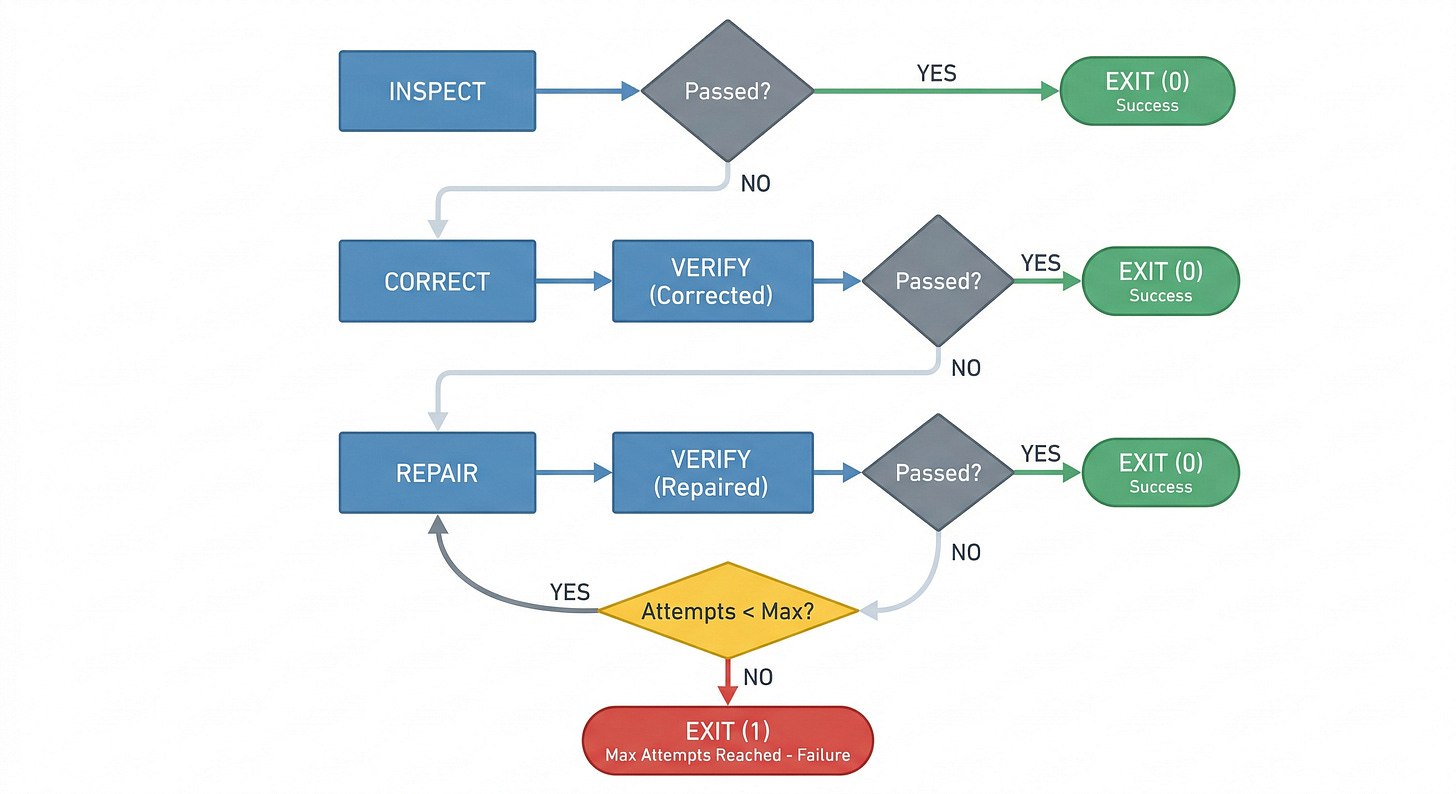
.
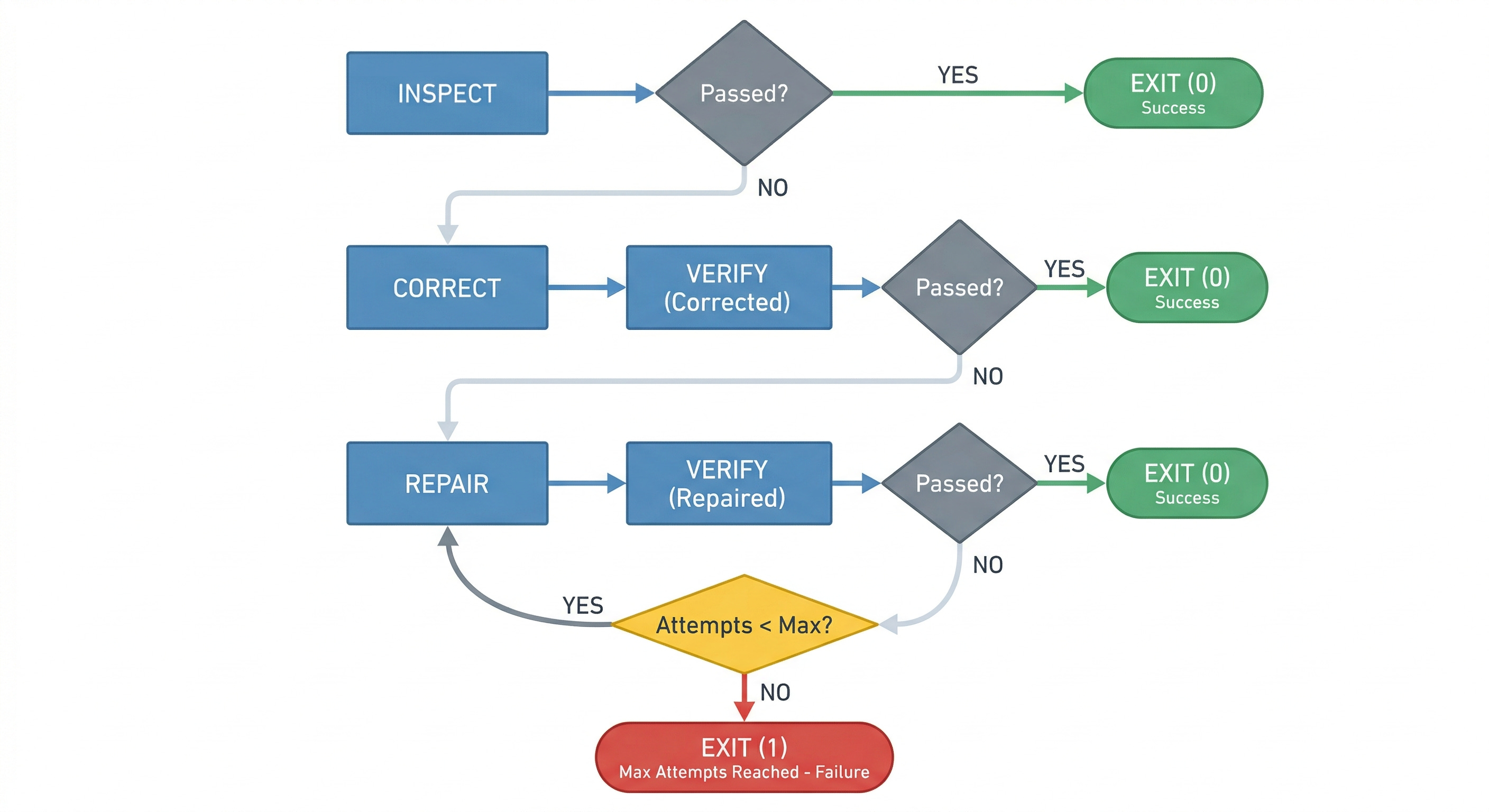
Most runs should be Inspect or Correct. Repair is the expensive, slow, less predictable path. The system is designed so that Repair is the exception, not the default.
In auto mode, escalation follows explicit conditions. Escalation is always forward — from cheaper, more predictable stages to more expensive, less predictable ones. An operator never skips backward from Repair to Correct, and never re-enters a stage it has already passed through (except Verify, which runs after each Repair attempt as the verification gate).
A run stops when one of four things happens: the declared scope has been exhausted, Verify passes, the next required step would exceed the operator’s authority, or repeated Repair attempts stop reducing the failure set. In the last two cases, the operator produces an evidence bundle — failing checks, tool output, and the current diff — and stops rather than improvises.
What we do not build
Autonomous scope or authority expansion. An operator that discovers new work mid-run or escalates its own authority is a bug, not a feature.
Self-certifying agent. No agent approves its own output. Final acceptance is a human decision.
Prompt-only replacements for project tooling. Operators call
make lint, not “please check if this code looks right.”
Automating engineering workflows
The goal is full automation of engineering workflows — linting, testing, documentation, code review, dependency management, security analysis — with humans reviewing the final diff.
CI triggers operators. A PR opens, CI runs the Reviewer. Each pillar runs in parallel, using the project’s real tools. The result is a structured report with verdicts per pillar.
Operators call project scripts. The operator does not reinvent
make lint. It callsmake lintand interprets the output. The project’s tooling is the source of truth.Deterministic fixes are applied automatically. Formatting, import sorting, simple lint autofixes — these are safe, predictable, and approved by project policy. They do not need an LLM or human approval.
Semantic repairs are proposed, not blindly applied. When an operator rewrites a docstring or adds a missing test, it proposes the change.
Verification is always the last step. After any change — deterministic or semantic — the project’s checks run again. The diff is clean or it is not.
Where this leads
The Reviewer is the highest-leverage piece of this system. It composes every other operator — linting, type checking, testing, documentation, architecture analysis — into a single coherent review. The full Reviewer covers many pillars: linting, docstrings, documentation, type annotations, dead code, tests, changelog, dependencies, architecture, security, commit hygiene, error handling, cognitive reduction, and more over time.
Each new pillar follows the same pattern: backed by sub-operators that wrap the project’s real tools, structured around the five-stage flow.
The ultimate goal is to get the Reviewer to a level of quality and coverage where building new features becomes a matter of writing a specification and letting operators implement it.
The logic is straightforward: if the Reviewer can reliably verify that code meets standards across all pillars then the verification side of development is solved. And if verification is solved, implementation becomes a conversation between a coding agent and the Reviewer, with a human approving the final result.
Spec-based development means:
A human writes a specification: what the feature should do, what the interface looks like, what constraints it must satisfy.
A coding agent implements the specification.
The Reviewer evaluates the implementation against all pillars.
If the review fails, the coding agent repairs.
The cycle repeats until the Reviewer passes.
A human reviews the final diff.
This is not a distant vision. Every pillar we add to the Reviewer, every sub-operator we build for a new tool, every improvement to the repair stage — all of it moves us closer to a system where the human’s job is to define what should be built and review whether it was built correctly, while operators handle the implementation and verification loop.
The foundation is composability. Because each operator is modular, because each tool has its own sub-operator, because the Reviewer composes them all through a uniform interface — adding a new capability is adding a new module, not redesigning the system.